
谷歌最新技术:通过搜索引擎,极大增强ChatGPT等模型的准确率(谷歌 技术)
由于Transformer的出现,使得ChatGPT等大语言模型在处理自然语言任务上的能力得到了大幅度提升。但生成的内容却包含大量错误或过时的信息,同时缺乏事实性评估体系,来验证内容的真伪。
为了全面评估大语言模型对世界变化的适应能力和内容的真实性,谷歌AI研究团队发布了一篇名为《通过搜索引擎知识增强大语言模型的准确性》的论文。提出了一种FRESHPROMPT的方法,可通过从搜索引擎获取实时信息,来提升ChatGPT、Bard等大型语言模型的准确性。
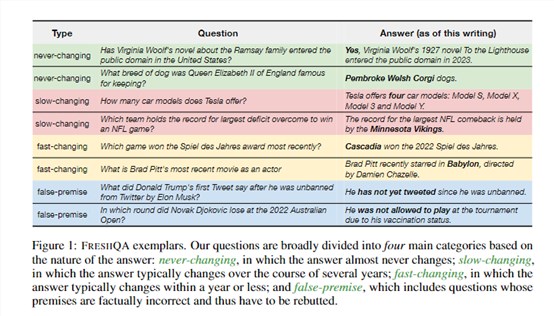
研究人员构建了一个新的问答基准测试集FRESHQA,其中包含600个各类真实问题,答案变化频率分为“永不改变”“变化缓慢”“变化频繁”和“错误前提”四大类别。
同时,还设计了严格模式和宽松模式两种评估方法,前者要求回答中的所有信息必须准确最新,后者仅评估主要回答的正确性。
实验结果显示,FRESHPROMPT明显提升了大语言模型在FRESHQA上的准确率。例如,GPT-4在FRESHPROMPT的严格模式帮助下,比原始GPT-4提升了47%准确率。
此外,相比于直接扩大模型的参数,这种融合搜索引擎的方法更加灵活,可以为已有模型提供动态的外部知识源。实验结果也证明FRESHPROMPT可以明显提升大语言模型在需要实时知识的问题上的准确率。
论文地址:https://arxiv.org/abs/2310.03214
开源地址:https://github.com/fresh大语言模型s/freshqa (正在筹备中,将很快开源)
从谷歌论文内容来看,FRESHPROMPT的方法主要由5大模块组成。
构建FRESHQA基准测试集
为了全面评估大语言模型对变化世界的适应能力,研究人员首先构建了FRESHQA基准测试集,其包含600个真实的开放域问题,根据答案变化的频率可以分为“永不改变”“变化缓慢”“变化频繁”和“错误前提”四大类别。
1)永不改变:答案基本不会改变的问题。
2)变化缓慢:答案每几年改变一次的问题。
3)变化频繁:答案每年或更短时间内就可能改变的问题。
4)错误前提:包含不正确前提的问题。
这些问题涵盖各种话题,具有不同的难度级别。FRESHQA的关键特点是答案可能会随时间变化,所以模型需要具备对世界变化的敏感认知能力。
严格模式与宽松模式评估
研究人员提出了两个评估模式:严格模式要求回答中所有信息必须准确最新,宽松模式仅评估主要答案的正确性。
这提供了更全面和细致的方式来测量语言模型的事实性。
基于FRESHQA评估不同大语言模型
在FRESHQA上,研究人员比较了涵盖不同参数的大语言模型,包括GPT-3、GPT-4、ChatGPT等。评估采用严格模式(要求无错误)和宽松模式(仅评估主要答案)。
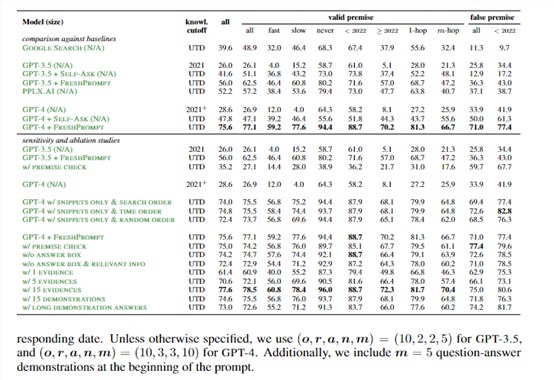
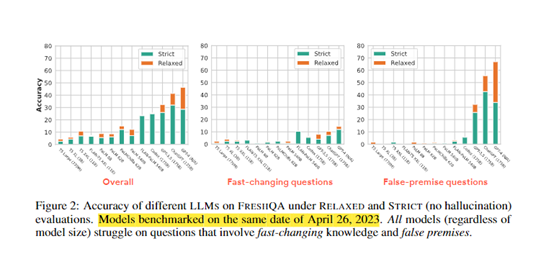
结果发现,所有模型在需要实时知识的问题上表现较差,尤其是频繁变化和错误前提的问题。这说明当前大语言模型对变化世界的适应力存在局限。
从搜索引擎中检索相关信息
为提高大语言模型的事实性,FRESHPROMPT的核心思路是从搜索引擎中检索问题相关的实时信息。
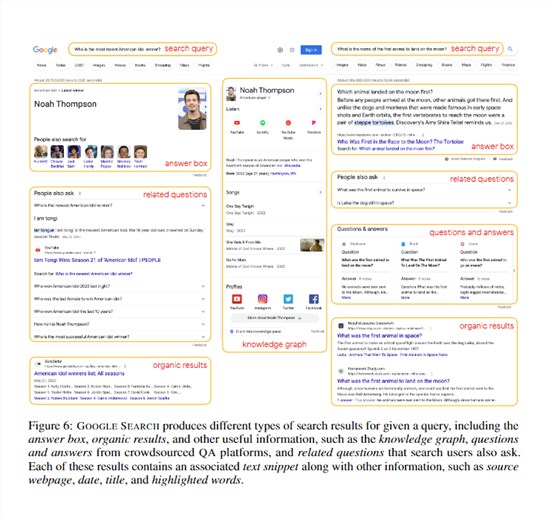
具体而言,给定一个问题,FRESHPROMPT会将其作为关键词查询谷歌搜索引擎,获取包含答案框、网页结果、“其他用户也问”等多种类型的搜索结果。
通过稀疏训练整合检索信息
FRESHPROMPT使用稀疏训练(few-shot learning)的方式,将检索到的各个证据以统一格式整合到大语言模型的输入提示中,同时提供几个示范,说明如何综合这些证据得出正确回答。
这样可以教会大语言模型去理解这个任务,并整合不同来源的信息来推理出最新准确的答案。
谷歌表示,FRESHPROMPT对提升大语言模型的动态适应能力具有重要意义,这也是大语言模型未来技术研究的一个重要方向。

本文素材来源谷歌论文
推荐站点
 88分类目录
88分类目录88分类目录专业提供网站网址免费提交收录,88分类目录是采用开放导航式的网站大全,收录国内外各行业优秀的网站网址,让网站在各大搜索引擎收录快排名靠前。
www.88dir.com 零目录
零目录零目录(www.dir0.com)专业的网站分类目录平台!为您提供网站分类目录索引及网址大全库的建立,是目前较为专业的网站分类目录平台,为用户打造大型正规分类目录网,提供高效便捷的网址存储和查询服务的分类目录网站。
www.dir0.com YY分类目录
YY分类目录YY分类目录全人工编辑的开放式网站分类目录,收录国内外、各行业优秀网站,旨在为用户提供网站分类目录检索、优秀网站参考、网站推广服务。
www.yydir.com 名人百科网
名人百科网名人百科网(mrenbaike.net)--为大家提供各行各业的名人资料、资讯、图片等,致力于打造国内专业的名人百科平台!
www.mrenbaike.net 菜鸟教程
菜鸟教程菜鸟教程提供了基础编程技术教程。 菜鸟教程的 Slogan 为:学的不仅是技术,更是梦想! 记住:再牛逼的梦想也抵不住傻逼似的坚持! 本站域名为 runoob.com, runoob 为 Running Noob 的缩写,意为:奔跑吧!菜鸟。 本站包括了HTML、CSS、Javascript、PHP、C、Python等各种基础编程教程。 同时本站中也提供了大量的在线实例,通过实例,您可以更好地学习如何建站。 本站致力于推广各种编程语言技.
www.runoob.com 中国社会公益网
中国社会公益网陕西省社会公益基金会是经陕西省民政厅批准的公募基金会,下设秘书处、公益项目部、筹款募捐部、宣传策划部、社会活动部、专项基金部、资金管理部、公关联络部、青年志愿者工作委员会、青年志愿者爱心乐团等部门机构
www.cpf.net.cn CNMO科技新媒体
CNMO科技新媒体CNMO=Connect More,致力于通过内容成为人与科技、人与产品、人与品牌、人与服务对接的桥梁,让产业、产品的价值与服务得到专业且有趣的解读和适配,引领用户畅享科技带来的美好生活!
www.cnmo.com 国外主机测评
国外主机测评国外主机测评,国外VPS、云服务器,国外服务器,国外主机的相关优惠信息、商家背景、网络带宽、线路走法、售前和售后技术支持等,是目前最好的一家国外主机评测平台。
www.zhujiceping.com 赵容部落
赵容部落赵容部落,一个收集国内,国外便宜主机,VPS,云服务器,独立服务器优惠促销信息,提供VPS新手教程,VPS评测,VPS代购代付服务的博客。
www.zrblog.net